Neben einigen direkt in den Regeln definierten literalen Token ( und dem STRING-Token s.u.) gibt in diesem Beispiel zwei Gruppen von Token. Die erste besteht aus den Token:
LINE_COMMENT //[^\r\n]*
PREPROCESSED #[^\r\n]*
USING using [^\r\n]*
Sie beginnen unterschiedlich und enden mit [^\r\n]*. Letzter Ausdruck beschreibt eine beliebig häufige Wiederholung von Nicht-Zeilenende-Zeichen. Insgesamt bezeichnen die Ausdrücke also Textabschnitte die mit "//" or "#'" oder "using" beginnen und sich bis zu den Zeilenenden erstrecken. Ein C++Programmierer erkennt sofort dass mit diesen Ausdrücken Zeilenkommentare, Präprozessordirektiven und using-Direktiven abgedeckt sind.
Die zweite Gruppe von Token besteht aus den Token:
DECLARATOR
DESTRUCTOR
Sie beginnen jeweils mit einem Ausdruck ähnlich dem folgenden:
(((\w+::)*\w+)::)?(\w+)
Dieser Ausdruck scheint unnötig kompliziert. Der einfachere Ausdruck:
(\w+::)*\w+
würde ebenso wie der erste Texte der Art:
Name
Class::Name
Class::Subclass::Name
usw.
erkennen, also Namen und Klassenmethoden.
Die komplizierte Form des Ausdrucks ermöglicht den Zugriffs auf Unterausdrücke. Jeder Klammerausdruck deckt einen Teil des insgesamt vom regulären Ausdruck erkannten Textes ab und dieser Teil kann im Interpreter ermittelt werden. Welcher Text welchem Klammerausdruck zugeordnet ist lässt sich am einfachsten mit Hilfe eines Tools erkennen, das im Hilfemenü unter Regex Test aufrufbar ist:
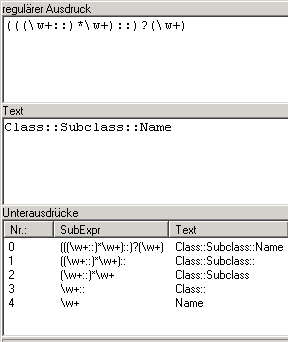
Aus der unteren Tabelle ist zu ersehen, dass der Unterausdruck mit dem Index 2 den Scope und der Unterausdruck mit dem Index 4 den Namen einer Klassenmethode enthält. Dies wird im guard-Projekt ausgenutzt um beide Strings in getrennte Klassenvariablen zu schreiben.
{{
m_sScope = xState.str(2);
m_sName = xState.str(4);
}}
Diese Variablen sind auf der Interpreter-Seite der IDE definiert. Sie werden in den später beschriebenen Funktionen print_at_enter und print_at_exit gebraucht.
Die vollständigen Definitionen sind:
DESTRUCTOR ::= (((\w+::)*\w+)::)(~\w+)
DECLARATOR ::=
(((\w+::)*\w+)::)(\w+) \//Scope(s) und Name, z.B.: CSub::CClass::Func
\s* \// optionale Leerzeichen
\([^)]*\) // Parameter, z.B.: ( int xi )
Man beachte die Möglichkeit einen komplexen Ausdruck über mehrere Zeilen zu verteilen und mit Kommentaren zu versehen.
TETRA ist in der Lage im Text eindeutig zu entscheiden welches der einander ähnlichen Token im Eingabetext vorliegt:
CguardParser::~CguardParser()
wird als DESTRUCTOR erkannt und
CguardParser::SetIgnoreScanner()
wird als DECLARATOR erkannt.
Die Erkennung arbeitet mit einem Algorithmus, der nach der größtmöglichen Abdeckung des Quelltextes mit dem regulären Ausdruck sucht. Auf diese Art ist es möglich Beschränkungen zu umgehen, die die von TETRA angewendete Topdown-Analyse sonst hat.